쿠버네티스의 구조

CNI
- 컨테이너 간의 네트워킹을 제어할 수 있는 플러그인을 만들기 위한 표준
- 다양한 형태의 컨테이너 런타임과 오케스트레이터 사이의 네트워크 계층을 구현하는 방식이 다양하게 분리되어 각자만의 방식으로 발전하게 되는 것을 방지하고 공통된 인터페이스를 제공하기 위해 만들어짐
- 쿠버네티스에서 Pod 간의 통신을 위해 CNI 사용 ; 기본적으로 'kubenet'이라는 자체적인 CNI 플러그인을 제공하지만 네트워크 기능이 매우 제한적 -> 3rd-party 플러그인 사용(Flannel, Calico, Weavenet, NSX 등)
namespace
- 쿠버네티스 클러스터 내의 논리적인 분리 단위

- 물리적으로 분리하는 것은 아님
- 쿠버네티스 오브젝드를 묶는 하나의 가상공간/그룹
- 다른 namespace의 pod이어도 서로 통시닝 가능하고 클러스터의 장애가 발생할 경우 모든 namespace가 타격 입음
namespace의 목적
- 네임스페이스별 리소스 할당량 지정

- 사용자별 네임스페이스 접근 권한
cluster
- 컨네이터화된 애플리케이션을 실행하는 노드(워커 머신)의 집합
- 모든 클러스터는 최소 한 개 이상의 마스터 노드 및 워커 노드를 가짐
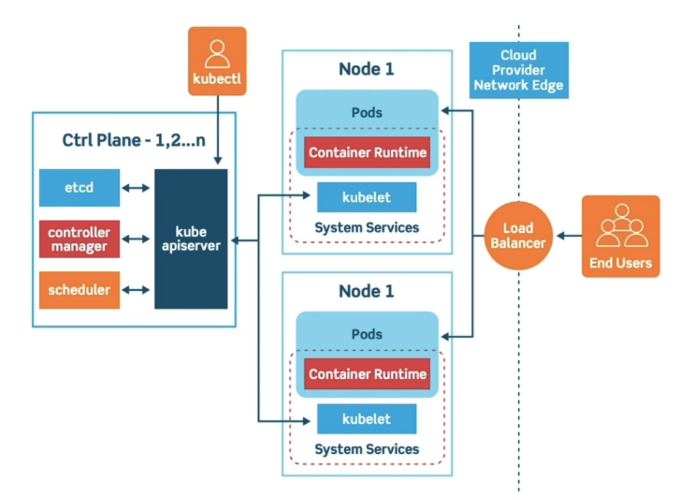
- 크게 컨트롤 플레인(Control Plane)과 노드(Node) 2가지 영역으로 구성
- 컨트롤 플레인 : 제어 영억, Master Node라고도 불림
- 노드 : 애플리케이션 컨테이너를 실행하는 역할을 한다고 하여 Worker Node라고 부르기도 함
컨트롤 플레인 : 마스터 노드

- 보통 1~n개(홀수개) 존재
- 클러스터의 상태를 관리하고 명령어를 처리하는 역할
- 각각의 컨트롤 플레인은 etcd, controller-manager, scheduler, kube api server라 하는 여러 구성요소 가짐
컴포넌트 분석
scheduler; Api 서버와 통신하는 컴포넌트, 각각의 노드(워커 노드)의 자원 사용 상태 관리
동시에 아직 노드가 배정되지 않은 새로 생성된 pod를 감지하고 새로운 워크로 드를 띄우는 역할
controller-manager; 여러 컨트롤러 프로세스 관리
kube api server; 쿠버네티스 리소스와 클러스터 상태 관리 및 동기화를 위한 API 제공.
etcd를 데이터 저장소로 사용
etcd; 분산 key-value 저장소로 클러스터의 상태 저장
노드 : 워커 노드

- 애플리케이션이 실질적으로 실행되는 공간
- 최소 1~n개로 구성, 내부에 존재하는 컴포넌트 구성도 모든 노드가 동일
- Container Runtime 위에서 Pod가 실행되는게 기본 형태, 그 외의 System 컴포넌트들이라 할 수 있는 kubelet, kube-proxy, network-addOn과 같은 여러 컴포넌트 돌아감
컴포넌트 분석
kubelet; 모든 노드에 기본적으로 설치되는 컴포넌트.
Api 서버와 통신하며 노드의 리소스 상태를 보고, 관리
Container Runtime과도 통신하며 해당 노드 내에 띄워지는 컨테이너의 라이프사이클 관리
CRI(Container Runtime Interface); kubelet이 다양한 컨테이너 런타임과 통신할 수 있도록 쿠버네티스가 자체적으로 준비한 인터페이스. docker에 대한 의존성을 줄이기 위한 목적
kube-proxy; 우선 클러스터 상에 오버레이 네트워크 구성 -> 내부적으로는 네트워크 프록시 및 내부 로드밸런서 역할 수행